Normalidad Asintótica
Cuando se viola el supuesto de que los errores se distribuyen normal con media 0 y varianza $\sigma^{2}I_{N}$ empezamos a tener problemas de inferencia estadística. ¿Por qué? Porque si no se cumple el supuesto de normalidad ya no sabemos si $\hat{\beta}$ se distribuye o no normal, y por ende no podemos calcular los estadísticos F o t. Lo bueno es que hay una solución, ya que este supuesto no es necesario cuando tenemos un tamaño de muestra "n" grande. En esta sección vamos a demostrar usando Stata, que con un n grande, tendremos que: $$\sqrt{n}(\beta - \hat{\beta}) \underbrace{\longrightarrow}_{Distribucion} N(0, AVar(\hat{\beta}))$$ Es decir, $\sqrt{n}(\beta - \hat{\beta})$ \textbf{converge en distribución} a $N(0, AVar(\hat{\beta}))$ Para demostrar esto, partimos de nuestro estimador $\hat{\beta}$ y llegamos a la forma $\sqrt{n}(\hat{\beta} - \beta )$, luego veremos a que convergen los términos restantes (Spoiler: Llegaremos a una función de la forma $A_{n}Z_{n}$, donde $A_{n}$ es una variable aleatoria que converge en probabilidad a una constante A, y $Z_{n}$ es una variable aleatoria que converge en distribución a una normal) y para terminar, usaremos el teorema de Slutsky para ver a que converge la función restante (la cual tendrá una forma tipo $A_{n}Z_{n}$). Entonces, partiendo de nuestros estimadores escritos en forma matricial: $$ \hat{\beta} = (X'X)^{-1}X'Y $$ $$ \hat{\beta} = \beta+ (X'X)^{-1}X'\epsilon $$ $$ \hat{\beta} - \beta = (X'X)^{-1}X'\epsilon (\frac{n}{n}) $$ $$ \hat{\beta} - \beta = (X'X)^{-1}X'\epsilon (\frac{n}{\sqrt{n}\sqrt{n}}) $$ $$ \sqrt{n}(\hat{\beta} - \beta) = (X'X)^{-1}X'\epsilon (\frac{n}{\sqrt{n}}) $$ $$ \sqrt{n}(\hat{\beta} - \beta) = (\frac{X'X}{n})^{-1} (\frac{X'\epsilon}{\sqrt{n}}) $$ Sabemos que $(\frac{X'X}{n})^{-1}$ converge en probabilidad a $E[X'X]^{-1}$, pero no sabemos nada sobre $(\frac{X'\epsilon}{\sqrt{n}})$, asi que vamos a ver: $$ (\frac{X'\epsilon}{\sqrt{n}}) $$ $$ \underbrace{X'}_{X}\underbrace{(\frac{\epsilon}{\sqrt{n}})}_{N(0,1)} $$ Por una parte gracias al teorema del limite central, esto converge a una normal, pero no sabemos cuales serán sus momentos muéstrales. Para saberlo, tomamos valor esperado: $$ E[{(\frac{X'\epsilon}{\sqrt{n}})}] = 0 $$ Y tomamos la varianza: $$ Var[{(\frac{X'\epsilon}{\sqrt{n}})}] = \frac{1}{n}X'Var(\epsilon)X $$ $$ Var[{(\frac{X'\epsilon}{\sqrt{n}})}] = \frac{1}{n}X'{\sigma_{\epsilon}}^{2}X $$ $$ Var[{(\frac{X'\epsilon}{\sqrt{n}})}] = {\sigma_{\epsilon}}^{2}\underbrace{(\frac{X'X}{n})}_{E[X'X]} $$ $$ Var[{(\frac{X'\epsilon}{\sqrt{n}})}] = {\sigma_{\epsilon}}^{2}E[X'X] $$ Dado lo anterior ahora sabemos que $(\frac{X'\epsilon}{\sqrt{n}}) \sim N(0,{\sigma_{\epsilon}}^{2}E[X'X])$ Y volviendo a nuestra ecuación inicial $$ \sqrt{n}(\hat{\beta} - \beta) = \underbrace{(\frac{X'X}{n})^{-1}}_{E[X'X]^{-1}} \underbrace{(\frac{X'\epsilon}{\sqrt{n}})}_{N(0,{\sigma_{\epsilon}}^{2}E[X'X])} $$ Y aqui es donde entra Slustky, ya que este teorema nos dice que Si $Z_{n} \underbrace{\longrightarrow}_{Distribucion} N(0,I)$ y $A_{n} \underbrace{\longrightarrow}_{probabilidad} A$ Entonces $$ Z_{n}A_{n} \underbrace{\longrightarrow}_{Distribucion} N(0, A\sum A') $$ En nuestro caso, $A = E[X'X]^{-1}$ Y $Z_{n} = (\frac{X'\epsilon}{\sqrt{n}}) \sim N(0,{\sigma_{\epsilon}}^{2}E[X'X])$ por lo que ya sabemos como terminar la demostración: El valor esperado: $$ E[Az_{n}] = AE[Z] = 0 $$ La varianza: $$ Var[{AZ_{n}}] = AVar(Z)A' $$ $$ Var[{AZ_{n}}] = E[X'X]^{-1}Var(Z)E[X'X]^{-1'} $$ Pero recordemos que $Z_{n} = (\frac{X'\epsilon}{\sqrt{n}}) \sim N(0,{\sigma_{\epsilon}}^{2}E[X'X])$, por lo que conocemos cual es la varianza de $Z$ $$ Var[{AZ_{n}}] = E[X'X]^{-1}{\sigma_{\epsilon}}^{2}E[X'X]E[X'X]^{-1'} $$ $$ Var[{AZ_{n}}] = {\sigma_{\epsilon}}^{2}E[X'X]\underbrace{E[X'X]^{-1}E[X'X]^{-1'}}_{I} $$ $$ Var[{AZ_{n}}] = {\sigma_{\epsilon}}^{2}E[X'X] = {\sigma_{\epsilon}}^{2} {\frac{(X'X)}{n}}^{-1} $$ Finalmente, conocemos la distribución y los momentos muéstrales de $\sqrt{n}(\beta - \hat{\beta})$ $$ \sqrt{n}(\beta - \hat{\beta}) D\longrightarrow N(0, {\sigma_{\epsilon}}^{2} {\frac{(X'X)}{n}}^{-1}) $$ Resumiendo, partimos del estimador de $\hat{\beta}$ para demostrar que cuando tenemos un n muy grande, sin importar como se distribuye el error, nuestro estimador $\hat{\beta}$ seguirá siendo útil para calcular nuestros estadísticos t y F\footnote{De hecho, siguiendo el mismo procedimiento se puede demostrar que $\hat{\beta}$ se distribuye normal con media $\beta$ y varianza ${\sigma_{\epsilon}}^{2}(X'X)^{-1}$. Sin el supuesto de normalidad, no conocíamos la distribución de $\hat{\beta}$, y por ende, no podíamos construir la t. Al demostrar que $\sqrt{n}(\beta - \hat{\beta}) D{\longrightarrow} N(0, AVar(\hat{\beta}))$ podemos construir la t y la F sin ningún problema.
Veamoslo en Stata:
clear
capture program drop MCO
program define MCO, rclass
args N
clear
set obs `N'
capture drop y x
gen x=runiform(0,8)
gen y = 0.5*x+runiform(0,5)
qui reg y x
return scalar beta = _b[x]
end

simulate Beta1000=r(beta), reps(1000) nodots: MCO 1000
save Beta1000.dta
simulate Beta10000=r(beta), reps(1000) nodots: MCO 10000
merge 1:1 _n using beta1000
kdensity Beta1000, n(500) generate(x_1000 f_1000) kernel(gaussian) nograph
label variable f_1000 "N=1000"
kdensity Beta10000, n(500) generate(x_10000 f_10000) kernel(gaussian) nograph
label variable f_10000 "N=10000"
graph twoway (line f_1000 x_1000) (line f_10000 x_10000)
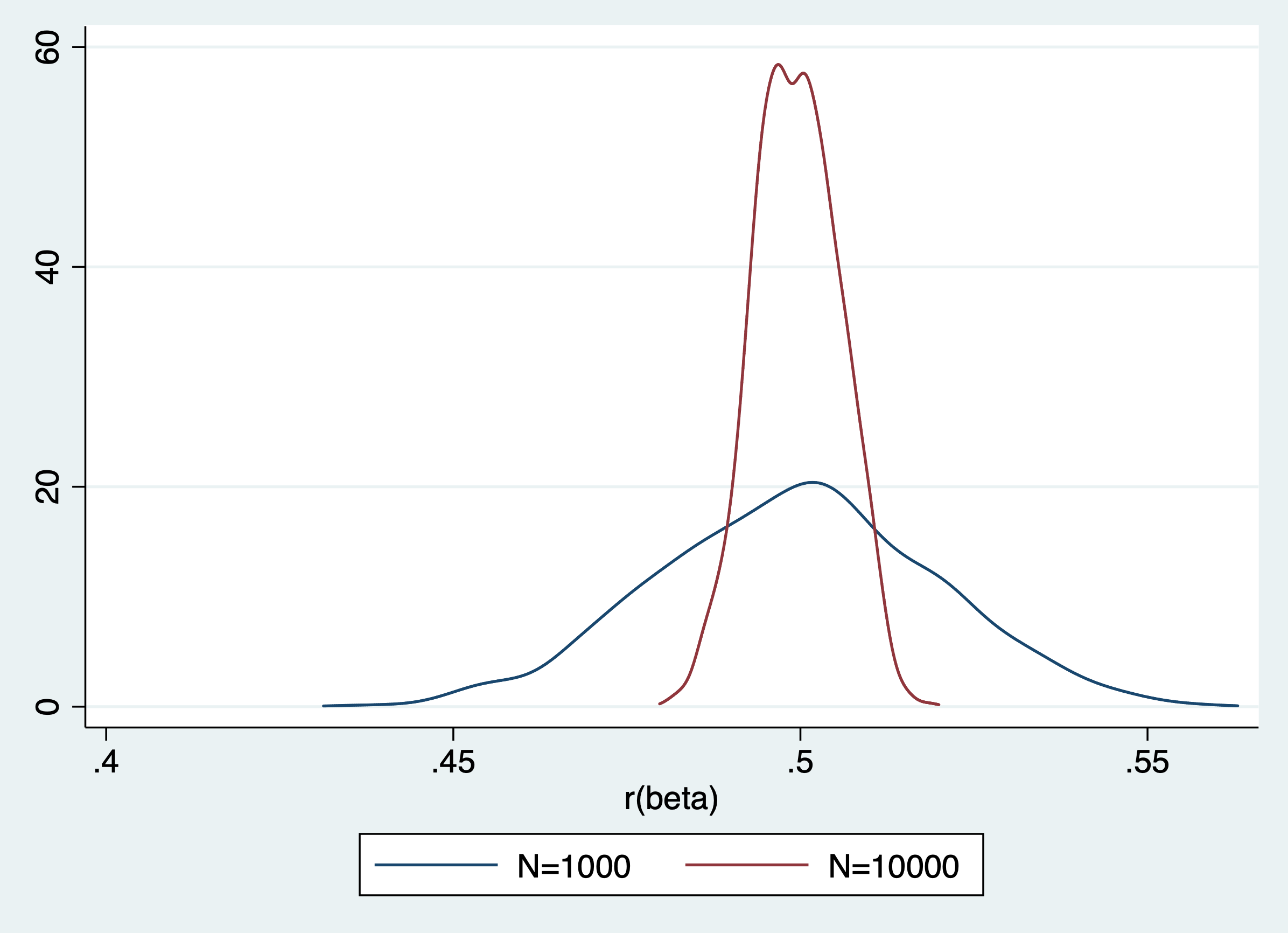
Como podemos ver nuestro estimador es consistente y a medida que aumenta la muestra, la probabilidad que la estimación se aleje del valor poblacional disminuye, pero como se había mencionado anteriormente esta el problema de que su distribución cambia a medida que cambia la muestra. La distribución del estimador con n = 10000 esta mucho mas concentrada.
Dado lo anterior optaremos por utilizar una version de los estimadores recentrados y escalados.
replace Beta1000=sqrt(1000)*(Beta1000-0.5)
replace Beta10000=sqrt(10000)*(Beta10000-0.5)
drop x_1000 f_1000 x_10000 f_10000
kdensity Beta1000, n(500) generate(x_1000 f_1000) kernel(gaussian) nograph
label variable f_1000 "N=1000"
kdensity Beta10000, n(500) generate(x_10000 f_10000) kernel(gaussian) nograph
label variable f_10000 "N=10000"
graph twoway (line f_1000 x_1000) (line f_10000 x_10000) (function normalden(x, sqrt(0.5)),range(-2 2)) , legend(label(3 "Distribución Normal" cols(3))
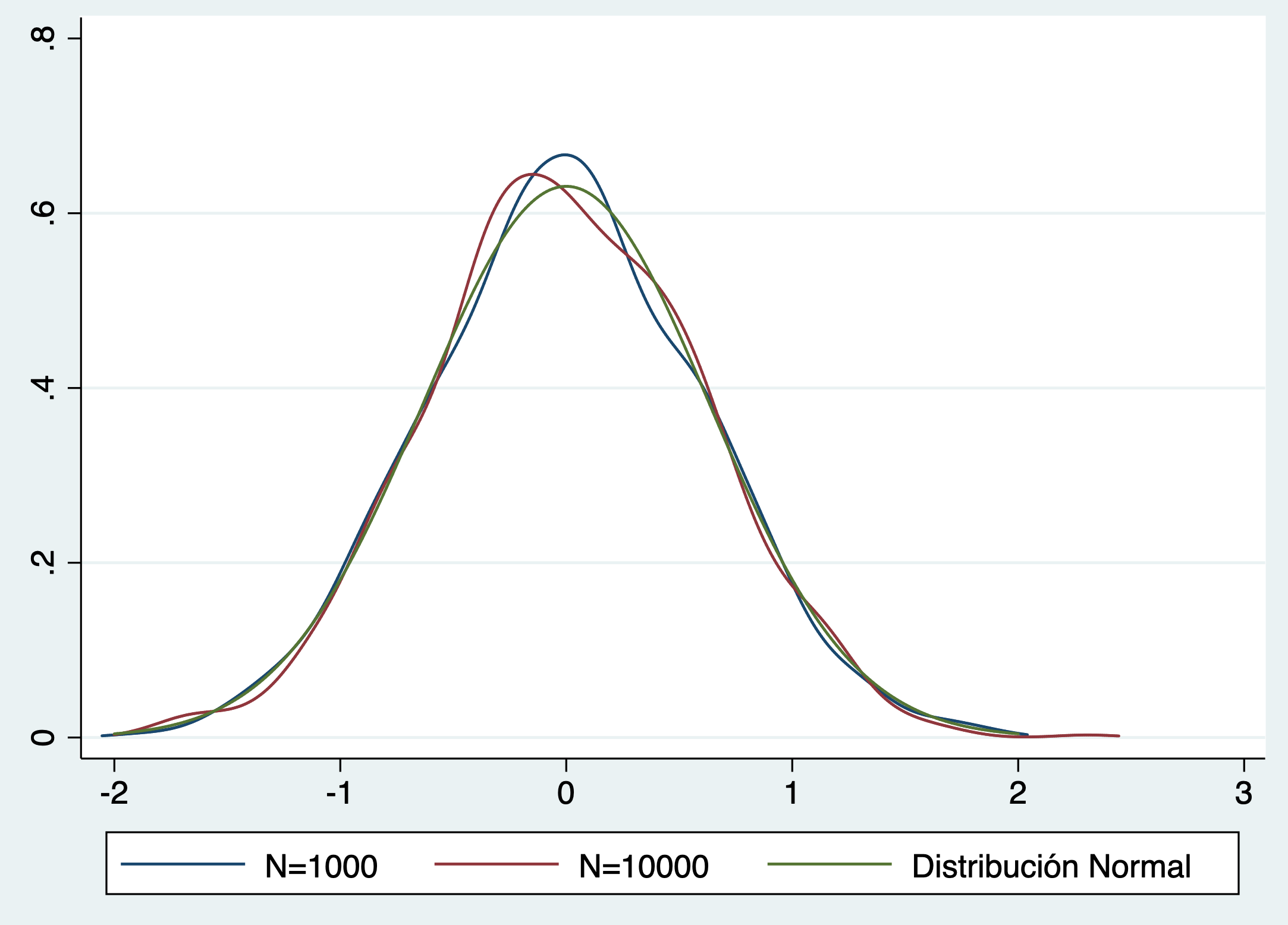
En esta ultima grafica vemos como los estimadores recentrados y escalados tienen una distribución prácticamente igual a la de una normal independiente del N. Ahora si podemos usar nuestros estadísticos f y t y hacer inferencia sin problema.
Bibliografía:
- Verbeek, M. (2004), A Guide to Modern Econometrics.
- Drukker, D. (2017), Consistencia y Normalidad Asintótica: Una Explicación con Simulaciones.
- Wooldridge, Jeffrey M. (2018), Introductory Econometrics: A Modern Approach, Sixth Edition, Cengage Learning.
- Montenegro, A. (2018), Econometría Intermedia y Básica.